View for Unstructured Datasets
An unstructured dataset is an imported dataset that does not contain any initial parsing steps. All parsing steps must be added through recipes that are applied to the dataset. During the import process, you disable the initial steps that are applied to imported datasets. Instead, these steps are added as the first steps of the auto-generated recipe that appears with the dataset in Flow View.
 |
Figure: Unstructured Dataset icons
Details options
Add:
Recipe: Add a recipe for this dataset.
Join: Join this dataset with another recipe or dataset. If this dataset does not have a recipe for it, a new recipe object is created to store this step.
Union: Union this dataset with one or more recipes or datasets. If this dataset does not have a recipe for it, a new recipe object is created to store this step.
View dataset details: Explore details of the dataset. See Dataset Details Page.
Edit name and description: (Available to flow owner only) Change the name and description for the object.
Remove from Flow: Remove the dataset from the flow.
All dependent flows, outputs, and references are not removed from the flow. You can replace the source for these objects as needed.
Note
References to the deleted dataset in other flows remain broken until the dataset is replaced.
Tip
You can also right-click the unstructured dataset to view all the menu options.
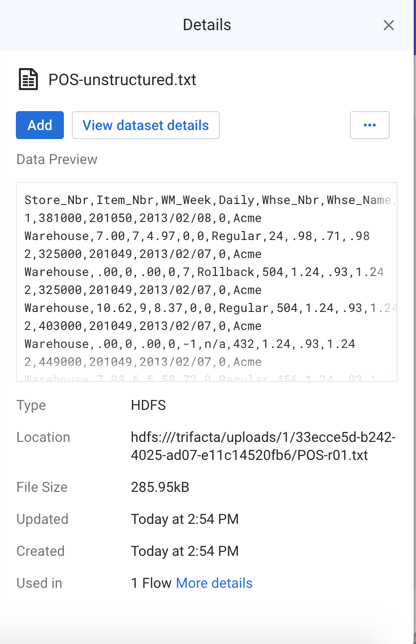
Figure: Unstructured Dataset view
Key Fields:
Data Preview: In the Data Preview window, you can see a small section of the data that is contained in the imported dataset. This window can be useful for verifying that you are looking at the proper data.
Tip
Click the preview to open a larger dialog, where you can select and copy data.
Type: Indicates where the data is sourced or the type of file.
Location: Path to the location of the imported dataset.
File Size: Size of the file. Units may vary.