View for Imported Datasets
When you select an imported dataset in Flow View, you can review its details in the context panel and select options from its context menu.
 |
Figure: Imported Dataset icon
Details options
The following options are available in the details context menu when you select an imported dataset.
Add:
Recipe: Add a recipe for this dataset.
Join: Join this dataset with another recipe or dataset. If this dataset does not have a recipe for it, a new recipe object is created to store this step.
Union: Union this dataset with one or more recipes or datasets. If this dataset does not have a recipe for it, a new recipe object is created to store this step.
View dataset details: Explore details of the dataset. See Dataset Details Page.
Replace: Replace the dataset with a different dataset or reference dataset.
Replace with dataset with Parameters: For datasets that are not parameterized, you can choose to replace with datasets with parameters.
Tip
You may find it useful to create your recipes with a single static dataset and then later replace with a dataset with parameters.
Edit name and description: (Available to flow owner only) Change the name and description for the object.
Edit custom SQL: After you have created a dataset using custom SQL, you can modify the SQL used to construct the imported dataset. See Create Dataset with Parameters.
Edit parameters: If your dataset contains parameters, you can change the parameters and their default values.
Remove structure: (If applicable) Remove the initial parsing structure. When the structure is removed:
The dataset is converted to an unstructured dataset. An unstructured dataset is the source data converted into a flat file format.
All steps to shape the dataset are removed. You must break up columns in manual steps in any recipe created from the object.
Remove from Flow: Remove the dataset from the flow.
All dependent flows, outputs, and references are not removed from the flow. You can replace the source for these objects as needed.
Note
References to the deleted dataset in other flows remain broken until the dataset is replaced.
Refresh Dataset: If available, this option refreshes the dataset's metadata with the latest source schema.
Note
When a dataset is refreshed, all samples associated with the dataset are deleted, whether the dataset has changed. Samples must be recreated in their recipes.
Note
If you attempt to refresh the schema of a parameterized dataset based on a set of files, only the schema for the first file is checked for changes. If changes are detected, the other files are contain those changes as well. This can lead to changes being assumed or undetected in later files and potential data corruption in the flow.
For more information, see Overview of Schema Management.
Tip
You can also right-click the imported dataset to view all the menu options.
When you select an imported dataset, you can preview the data contained in it, replace the source object, and more from the right-side panel.
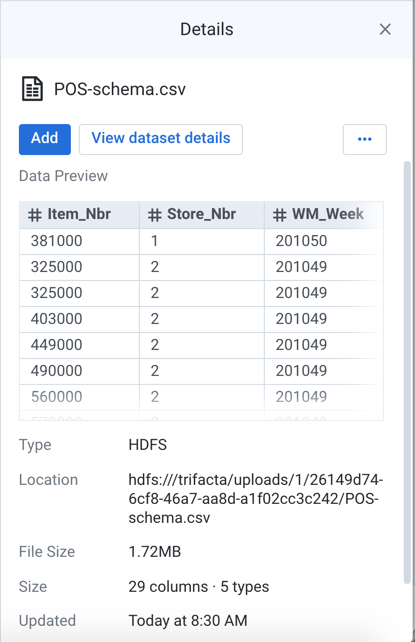
Figure: Imported Dataset view
Key Fields:
Data Preview: In the Data Preview window, you can see a small section of the data that is contained in the imported dataset. This window can be useful for verifying that you are looking at the proper data.
Tip
Click the preview to open a larger dialog, where you can select and copy data.
Type: Indicates where the data is sourced or the type of file.
Location: Path to the location of the imported dataset.
File Size: Size of the file. Units may vary.
Column Data Type Inference:
Note
This field is only applicable to datasets imported from relational sources.
enabled- Data types have been applied to the dataset during import.disabled- Data types were not globally applied to the dataset during import. However, some columns may have had overrides applied to them during the import process. See Import Data Page.
ConnectionName:If the data is accessed through a connection, you can click this link to review connection details in the right-side panel.
More details: Review details on the flows where the dataset is used.