Run Jobs
When your recipe is ready, you can execute a job to generate output results of your transformations applied to your dataset.
For more information, see Overview of Job Execution.
Prerequisites
To generate results, you must define an output object, which includes information about output format, location, and other settings.
You can define an output as part of the process of running a job.
For more information, see Create Outputs.
Run Job
From the Transformer page, click Run.
In the Run Job page, a running environment is selected for you.
Tip
Unless you have a specific reason to do so, you should use the default running environment, which is chosen based on the size of the job for you.
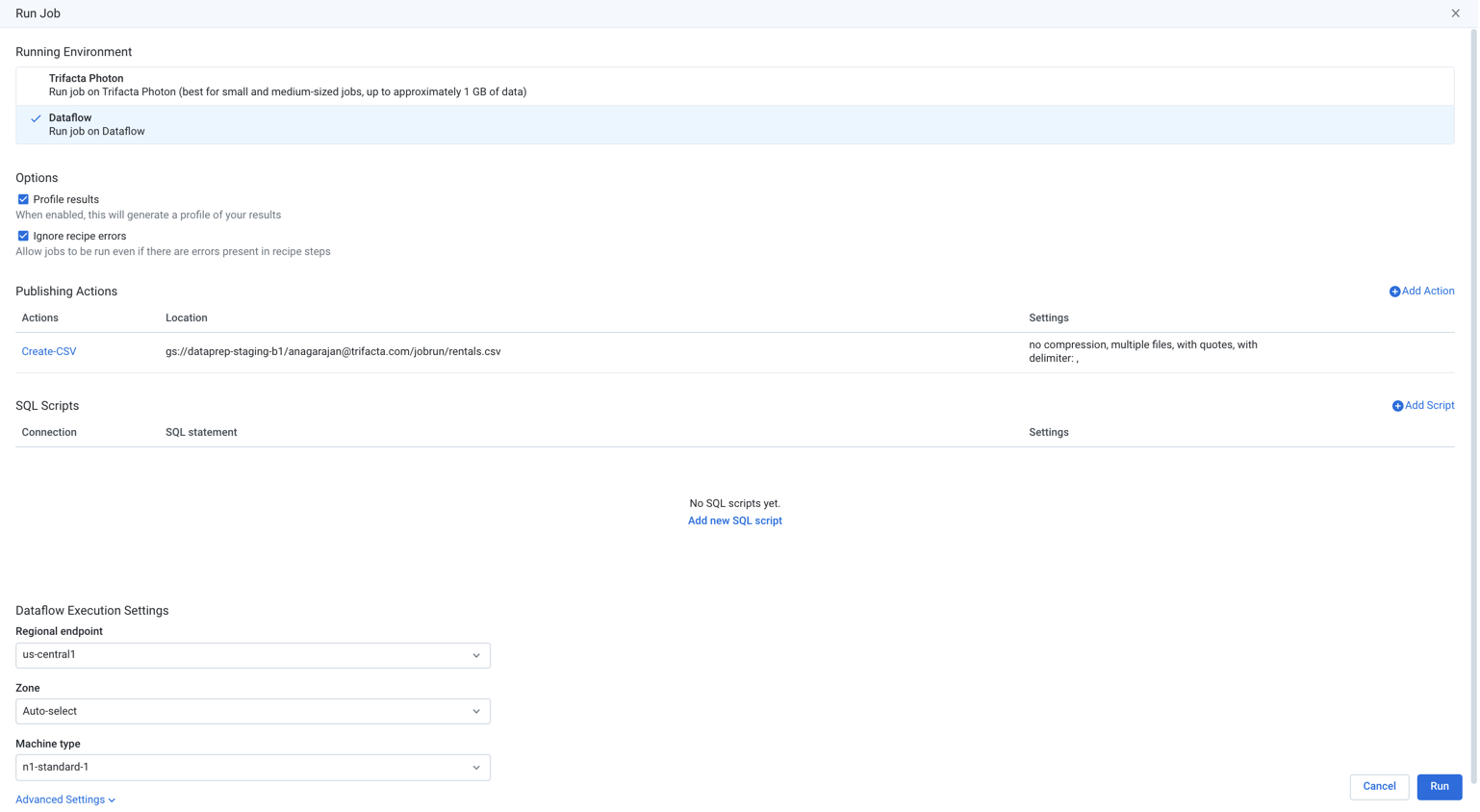
Figure: Run job page
Note
When you select the Spark environment, the Advanced environment options are displayed. These options pertain to various limits that Spark can apply to the runtime execution of the job.
Options:
Profile results: A visual profile of your output results can be generated for review. For more information, see Profile Results.
Ignore recipe errors: When selected, the job is permitted to execute even when there are known errors present in the recipe.
To add a new publishing destination, click Add Action.
In the publishing action page, specify the connection and location.
For the specified output, set the preferred settings in the right-side panel and click Add.
See Create Outputs.
If needed, you can define SQL scripts that are executed before or after generation of your output objects. To add SQL scripts, click Add Scripts.
To execute the job to generate the specified output, click Run.
To cancel a job in progress, click Cancel job in the Job Details page.
For more information, see Run Job Page.