Alteryx Engine y AMP: las principales diferencias
En el artículo Alteryx AMP Engine, describimos a Alteryx Engine y al nuevo Alteryx Multi-threaded Processing (AMP). Ahora profundizaremos en las principales diferencias entre los dos.
Diferencias en el procesamiento de datos
La arquitectura del motor original permite principalmente el procesamiento de un solo hilo, en el cual tus datos se procesan de un registro a la vez secuencialmente. Por otro lado, el nuevo concepto AMP permite un procesamiento masivo de varios subprocesos. Los registros se procesan en paquetes de 4 MB para una ejecución más rápida y en paralelo, lo que puede afectar al orden de los registros de salida.
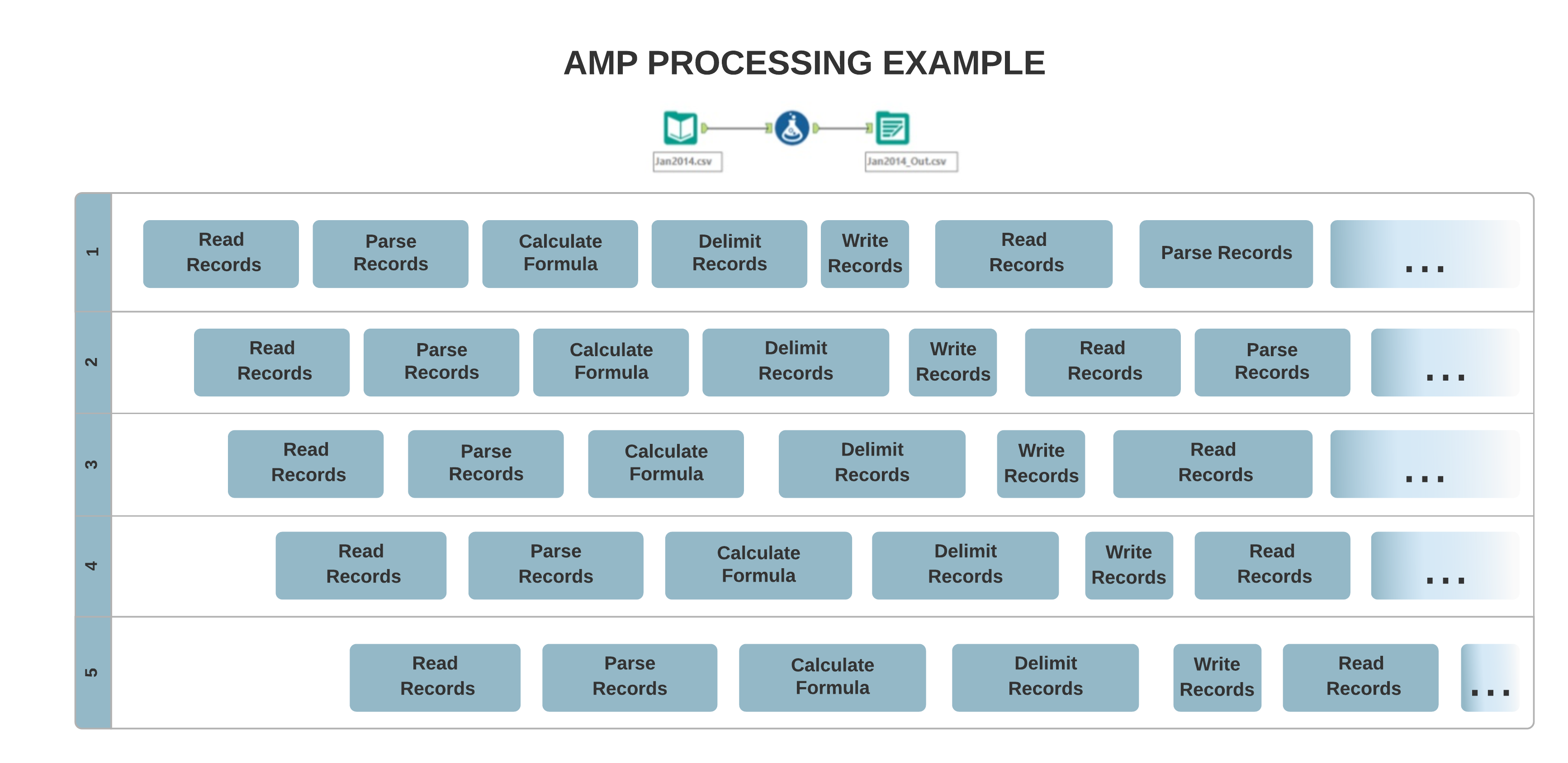
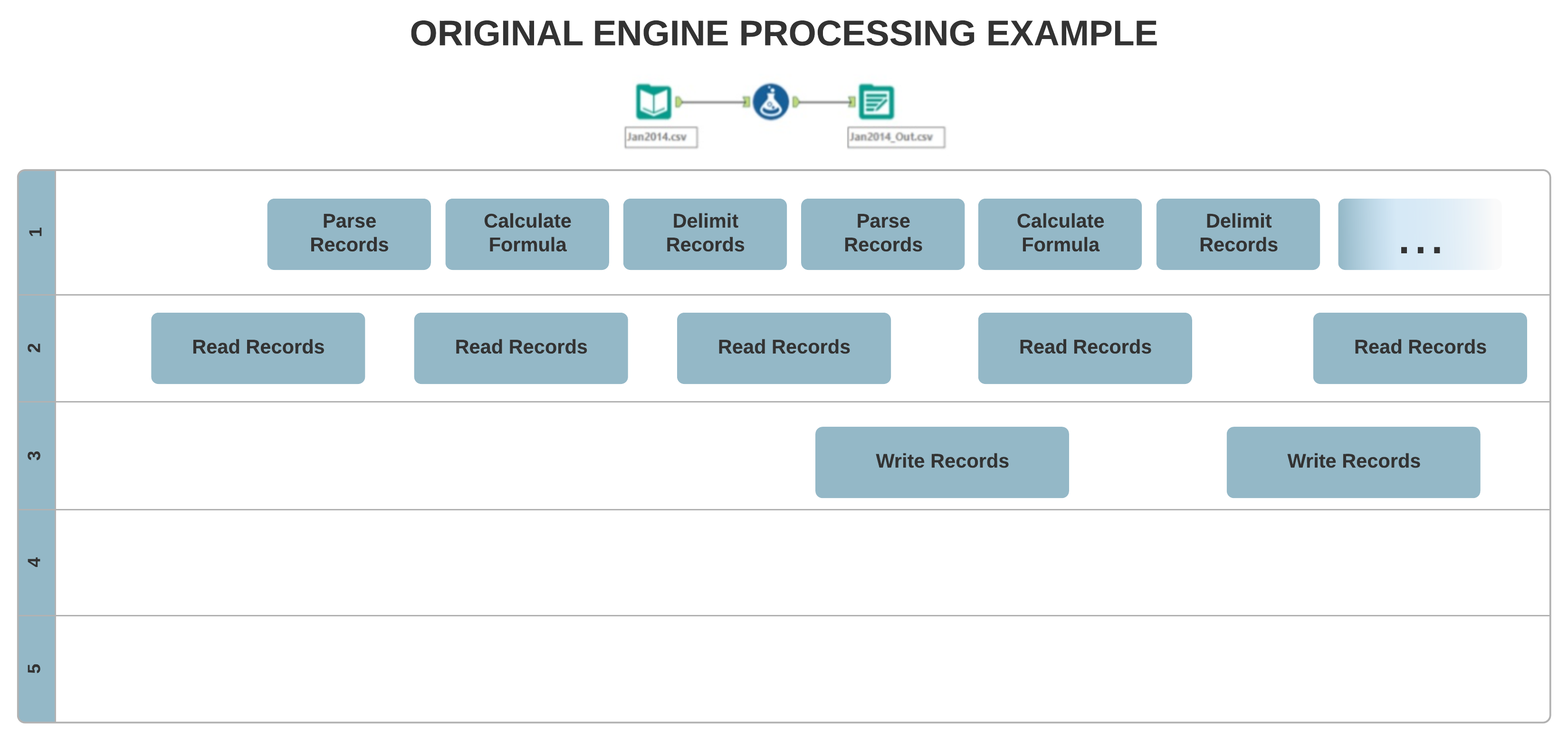
Diferencias en la entrada
Los archivos CSV que contiene un campo con nuevas líneas entre comillas fallan si no activas la opción adicional Solo AMP: los campos entre comillas pueden tener líneas nuevas.
Límite de registros
El ajuste de tiempo de ejecución en la configuración del flujo de trabajo Límite de registros para todas las entradas se activa con AMP en las siguientes herramientas:
Datos de entrada
Entrada de texto
Generar filas
Entrada de macro
La compatibilidad con AMP a nivel de herramienta para el límite de registro en la herramienta Entrada dinámica se agregó con el parche 2 de la versión 2021.1 y todos los lanzamientos posteriores.
Diferencias en la salida
Cuando un flujo de trabajo se ejecuta con el AMP Engine, es posible que varias herramientas generen registros en un orden diferente al del motor original. Entre esas herramientas están:
Tabulación cruzada
Limpieza de datos (al eliminar filas nulas)
Unir
Unir múltiple
Fórmula de filas múltiples
Generación de polígonos
Total acumulado
Ordenar (cuando el orden de diccionario se utiliza con caracteres especiales)
Resumir (cuando se utiliza la opción "Agrupar por")
Mosaico
Apilar
Único
Si tu flujo de trabajo requiere que los registros de las herramientas anteriores estén en un orden específico para las operaciones posteriores, Modo de compatibilidad del motor está disponible para mantener el mismo ordenamiento que con el motor original. Usa esto después de considerar el flujo de trabajo específico, principalmente al migrar flujos de trabajo creados con el motor original para que se ejecuten con AMP Engine.
Las funcionalidades o configuraciones específicas que no se convirtieron para AMP se revierten al motor original para poder funcionar. Por lo tanto, los flujos de trabajo que contienen ambas herramientas convertidas y no convertidas para AMP se ejecutarán sin problemas con AMP.
Si tienes preguntas sobre qué herramientas se convirtieron para AMP, consulta Uso de herramientas con AMP.
Con el motor original, las herramientas están más conectadas y dejan de funcionar en cuanto no hay ninguna otra etapa siguiente en el flujo de trabajo. Con AMP funcionando en paralelo, las herramientas pueden no detenerse cuando no haya ninguna etapa siguiente en el flujo de trabajo. La suposición es que con las siguientes etapas vacías, el flujo de datos no se tiene en cuenta. El mensaje de registro solo se utiliza para información. Si el número de registros en el flujo es importante para ti, puedes poner una herramienta Prueba en él e indicarle que te envíe un mensaje de error si no se obtiene el número correcto de registros.
Rendimiento de lectura
Un archivo YXDB escrito con AMP Engine se lee más rápido que un YXDB escrito con el motor original. El archivo .yxdb escrito con el motor original se lee más lentamente con AMP habilitado. Sin embargo, los formatos siguen siendo compatibles.
Utiliza formatos de archivo .xlsx, .csv, .yxdb y SQLite con AMP, ya que admiten datos de lectura y de varios hilos de procesamiento.
La conversión de registros y el empaquetado entre el motor original y AMP al leer archivos Zip tiene un costo de rendimiento. Esto podría causar que los archivos .zip más grandes se lean mucho más lento con AMP.
Concejo
Cuando se abre en un editor de texto, un archivo .yxdb escrito con AMP tiene "Alteryx e2 Database file" al principio del contenido del archivo. En cambio, un archivo escrito con el motor original solo muestra "Alteryx Database File" en la misma ubicación.
Rendimiento de escritura
Para mejorar el rendimiento del motor original (hacer que AMP escriba un archivo YXDB creado con el motor original), ve al menú de Datos de salida - Configuración. Allí tienes la opción de crear la versión del archivo YXDB compatible con la versión de Designer 18.1 y versiones anteriores.
La herramienta Salida se comporta de manera diferente con los registros que contienen datos de SpatialObj cuando se guarda el archivo CSV con el motor original y con AMP Engine. Aunque AMP escribe los datos de SpatialObj en el archivo cuando se guarda como un archivo CSV, el motor original no lo hace. Esta diferencia provoca diferencias en el tamaño del archivo y es posible que experimentes un rendimiento reducido.
Si es necesario, una solución alternativa es eliminar los datos espaciales de los registros usando la herramienta Seleccionar. Esto permite que ambos motores se completen con una duración similar.
Perfilado del rendimiento
El perfilado del rendimiento por herramienta con AMP está disponible con la versión de Designer 2021.3 y versiones más recientes.
Rendimiento de la herramienta R
AMP transfiere datos hacia y desde R en el formato del motor original. Esta doble conversión lleva tiempo. El tiempo de ejecución de una herramienta R puede ser más lento con AMP que con el motor original, pero es más rápido si se ejecuta más de una rama simultáneamente.
Herramientas Entrada de texto y Campo automático
AMP soluciona un problema histórico en el que el tamaño del campo puede no ser lo suficientemente grande cuando se procesa con una herramienta posterior. No es necesario agregar herramientas Seleccionar para cambiar los tipos de datos cuando los datos resultantes superen la longitud de los tipos de datos originales. AMP crea el tamaño de campo máximo para cadenas y números enteros a fin de que las operaciones posteriores tengan el espacio necesario para contener valores más grandes.
Herramienta Desacelerar
Aunque la herramienta Desacelerar no se convirtió completamente para AMP, puedes usarla junto con la herramienta Descargar (Desacelerar va primero).
Herramienta Coincidencia difusa
La herramienta Coincidencia difusa puede tener resultados diferentes con el motor original y AMP. Utilizando AMP, los registros se comparan usando un método alternativo. El orden de las coincidencias puede ser diferente y la salida puede estar en orden inverso. Existe un problema de rendimiento conocido en el que la herramienta Coincidencia difusa tiene peor rendimiento con AMP que con el motor original.
Herramienta RegEx
AMP utiliza los estándares de codificación Unicode y Perl, en los cuales los caracteres $, +, <, =, >, ^, | y ~ no califican como signos de puntuación. Cuando se utiliza la función de fórmula REGEX_Replace o la herramienta RegEx para filtrar la puntuación mediante el conjunto RegEx [[:punct:]], con AMP es necesario cambiar la expresión.
Ejemplo
REGEX_REPLACE([_CurrentField_],'[[:punct:]]|[\$\+<=>\^`\|~]','')
Herramientas de agrupación y herramientas de bloqueo
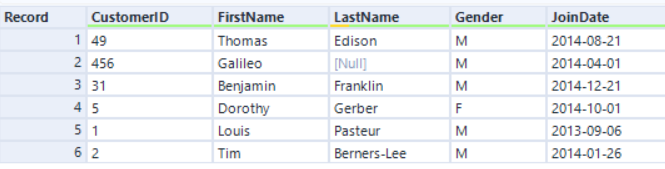
El algoritmo de la herramienta Unir con el motor original se basa en el método de unión de ordenar-combinar, en el cual los registros siempre vienen ordenados. Con AMP, el algoritmo nuevo de la herramienta Unir se basa en un método de unión Hash, y los registros salen desordenados. Por ejemplo...

Entrada izquierda:
Entrada derecha:
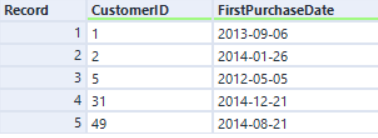
Si se une por la columna CustomerID con el motor original, los registros se ordenan según el campo CustomerID:

Mientras que con AMP, los registros son los mismos, pero en un orden diferente:

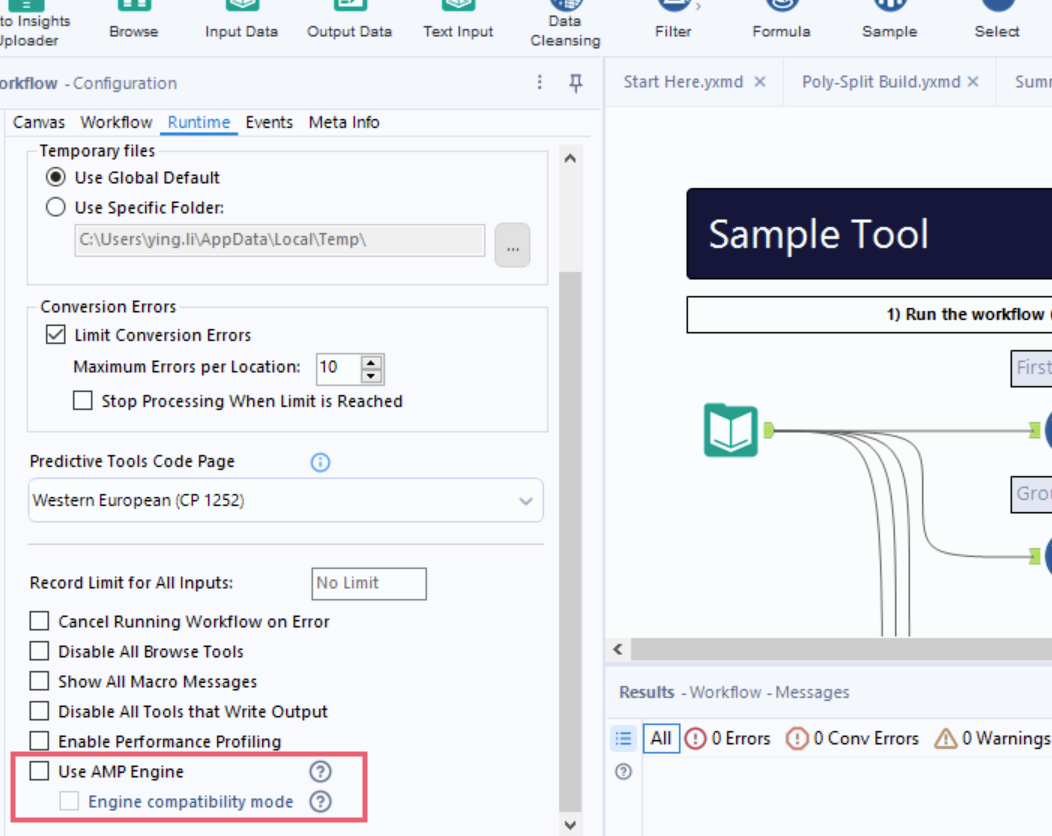
Si necesitas que la salida de la herramienta Unir esté ordenada, agrega la herramienta Ordenar después de la herramienta Unir o activa el ajuste Modo de compatibilidad de motor en Configuración del flujo de trabajo> Tiempo de ejecución, debajo de la opción Usar AMP Engine.
Macros iterativas
Una diferencia entre el motor original y AMP puede ocurrir cuando una herramienta dentro de una macro informa de un error. Al ser de un solo subproceso, el motor original se detiene si se produce un error en una macro. AMP funciona hasta que la salida iterativa está vacía o se produce el número máximo de iteraciones. Debido a una mayor cantidad de iteraciones, puedes enfrentarte con las siguientes situaciones:
La cantidad de errores (si los hay) puede ser mayor con AMP.
La cantidad de registros puede ser mayor con AMP.
El esquema de salida puede ser diferente con AMP.
Herramienta Fórmula
Las funciones ConvertFromCodePage y ConvertToCodePage de la herramienta Fórmula aceptan cadenas como parámetro y devuelven cadenas como resultado, por lo que no es posible distinguir cómo se codifica la cadena. Existe una diferencia en la salida de la herramienta Fórmula cuando estas funciones se utilizan con el motor original o con AMP.
Una representación binaria diferente de los datos de entrada se debe al uso interno que hace AMP de las cadenas codificadas en UTF-8. Cuando se importan datos con una codificación diferente, no hay forma de restaurar los datos originales. El motor original almacena cadenas como cadenas codificadas Latin-1 o UTF-16 que se utilizaron como búfer y permiten volver a convertir los datos correctamente.
Complementos para la herramienta Fórmula
AMP aún no admite complementos (add-ins) para la herramienta Fórmula. Si necesitas ejecutar un flujo de trabajo que contiene esa funcionalidad, ejecútalo con el motor original.
Importante
Formula Add-Ins are supported via AMP as of the 2023.2 release.
Aplicación analítica
Las aplicaciones que utilizan la herramienta Mapa para seleccionar desde una capa de referencia espacial en una aplicación analítica deben seguir utilizando el motor original.
Esperar flujos iguales
Con el motor original, Esperar flujos iguales sigue siendo una macro CReW. Con AMP se ejecuta como una herramienta nativa.
Ejecución paralela de ramas y orden de ejecución de herramientas
Algunos flujos de trabajo leen de un archivo y, luego, le vuelven a escribir al mismo archivo. Esto requiere secuenciación para asegurar que la lectura se completo antes de que se pueda iniciar la escritura. Del mismo modo, un flujo de trabajo que escribe varias hojas en un archivo .xlsx debe escribir las hojas de a una. Alteryx Designer proporciona la herramienta Bloquear hasta finalizar para ayudar a dividir el trabajo en fases que no se interpongan.
Se aplica la misma solución para la herramienta Correo electrónico cuando se utilizan archivos de salida de ramas anteriores como archivo adjunto. Debes esperar a que finalice el procesamiento de datos y, a continuación, agregarlo como archivo adjunto a la herramienta Correo electrónico.
Cuando trabajas con un flujo de trabajo con varias ramas (flujos ampliamente separados de las entradas a las salidas), hay que colocar la herramienta Bloquear hasta finalizar en la rama del flujo de trabajo con la herramienta de entrada con el número de Id. más bajo. Esto garantiza que todas las ramas posteriores esperen para ejecutar hasta que termine la rama anterior y la herramienta funcione según lo esperado.
Funcionalidad disponible
Para obtener más información sobre las funcionalidades de herramientas específicas, dirígete a:Uso de herramientas con AMP.